2025年11月4日
KNIMEを活用した、新たな知見を引き出す経理データの設計
塩野義製薬株式会社DX推進本部データサイエンス部所属、データエンジニアの直原です。本記事は、以前掲載した「SHIONOGIデータ基盤の構成と機能」の続編です。今回は、データサイエンス部が運営するSHIONOGIデータ基盤(Central Data Management Platform、以降CDM基盤)を活用して、私たちデータエンジニアが業務担当者とどのように関わっているか、一例をご紹介します。
SHIONOGIは中期経営計画 “STS2030 Revision” において、ヘルスケアプロバイダーへの変革を掲げました。変化への柔軟な対応が求められる中、私たちデータエンジニアは、データを通じて社内の見える化を推進するために、業務担当者と一緒に、データモデリングと収集を繰り返しながら、管理していくべきデータについて検討しています。このデータ設計の検討に、CDM基盤が役立っています。例えば、CDM基盤を通じて、今ある業務システムのデータを収集し、KNIMEで加工し可視化してみて、何を見たいかの議論に活用します。また、自動更新させながらデータを蓄積してみることも自分達で出来るので、一定期間ダッシュボードとして業務適用しながら、必要性について議論していくこともあります。
以上のようなCDM基盤の活用事例として、社内「データハッカソン」での経理財務部員との協業事例について紹介したいと思います。私たちデータエンジニアは、毎年データリテラシーを向上するためのスキルアップイベントを企画しており、昨年度に開催したデータハッカソンでは、私は経理財務部員と同じチームになったので、経理データの課題の改善案の検討に取り組みました。まだ、業務利用の軌道に乗った状況には至れていませんが、データを設計する上でのポイントや、データの貯め方を変えるための技術について、個人的にとても勉強になったので、共有したいと思います。
経理データは社内の管理会計システムを通じて収集されていますが、このシステムでは、最新のビジネス状況を反映した数字である見込の金額が常時上書き更新され、最終的には実績に置き変わる仕組みです。予算残高として見込の差分を見ることが出来、予算管理上とても便利なデータなのですが、一方で、過去に振り返って分析しようと思うと見込の変遷を月単位では追うことが出来るが、日単位などのより細かい粒度では追うことが出来ず、計画性の良し悪しを詳細に振り返ってコストコントロール力を更に高めるようなことが出来ません。そこで、データの貯め方を上書き更新されないように変えて、見込を時系列に分析出来るようにすれば解決できるのではないかと考えました。
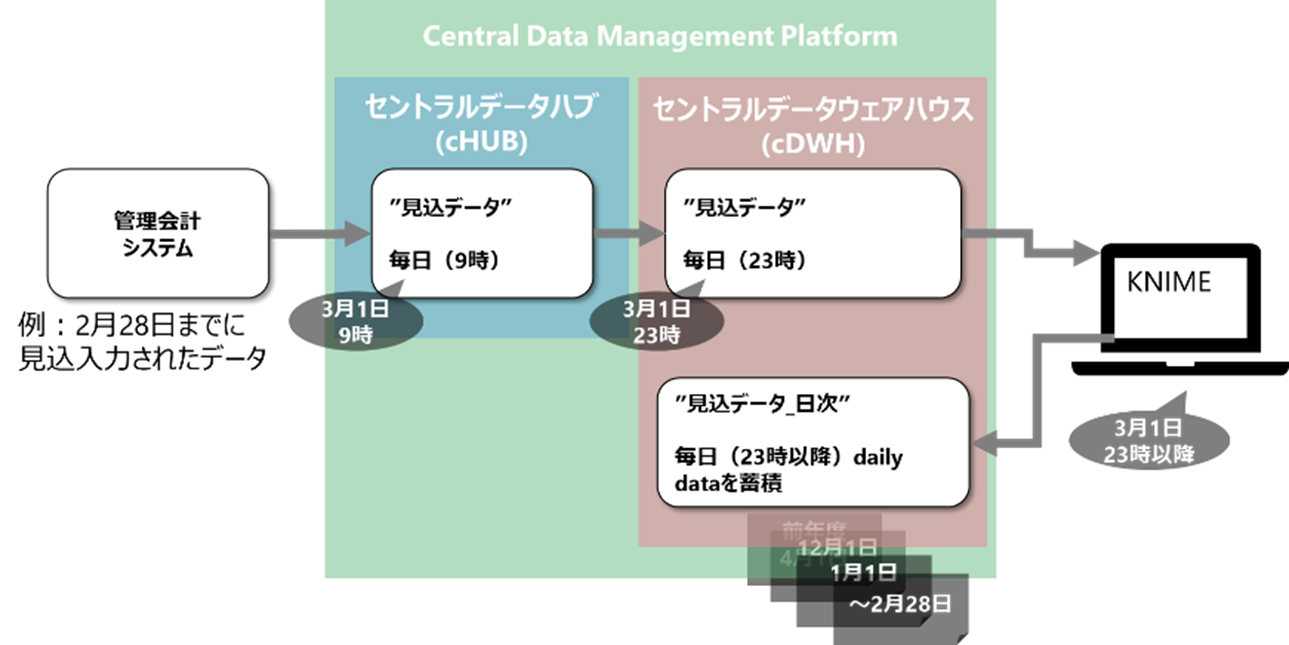
図1:経理データの「貯め方」の再構成案
構成の詳細
設計方針は下記の3点です。
①いつのデータか時系列に見えるように、データを取得した日の日付データをカラム追加し、履歴情報として保持すること。
②日次の行追加でデータ量が増えていきハンドリングし辛くなるため、不要なデータは削除すること。
③明細データでデータ量が多く更新時のKNIME処理が遅いので、出来る限りデータベース上でデータを操作してからKNIMEにロードすること。
加えて今回は、前処理済のデータがすでにデータウェアハウス(セントラルデータウェアハウス、以降cDWH、詳細はこちら:SHIONOGIデータ基盤の構成と機能)内にあったので、これを源泉として利用しました。cDWHからcDWHへの格納となり、データ連携の回数が増える分、直接データレイク(セントラルデータハブ、以降cHUB、詳細はこちら:SHIONOGIデータ基盤の構成と機能)から収集するよりも最新性は落ちると感じましたが、今回は振り返り出来るかどうか検討することが目的でありリアルタイムにモニタリングしたい要件は無かったため、前処理のワークフローを作成する作業を減らすことを優先しました。もし今後アウトプットの即時性を高めたくなったら、cHUB或いは業務システムを直接の源泉として連携させる必要があると思います。
①履歴情報の追加
履歴情報を追加するためには、蓄積するデータがいつのデータか、正確に把握する必要があります。特に今回は複数のデータ連携を介するため、状況把握を丁寧に実施しました。例えば図1の様に、2月28日までに入力された見込のデータは、次の日の朝9時からCDM基盤への連携が始まり、一旦cHUBに蓄積されます。次に、その日の深夜23時から、分析用のcDWHに取り込まれます。このデータに対して履歴情報を追加する加工を施しながら蓄積していくことになりますから、今回の処理が実施されるのは3月1日の深夜23時以降となります。つまり履歴情報を追加する際には、処理する「今日」の日付から「-1」ないし、処理が重くて時間を要し結果的に実行完了が3月1日を跨ぐような場合には「-2」、日付をシフトする処理が必要ということです。これを考慮して作成したワークフローが以下です。
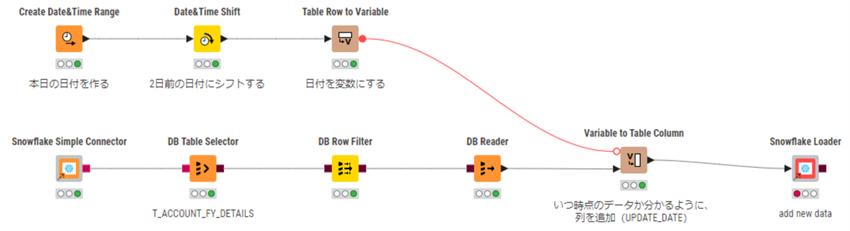
図2:履歴情報追加のKNIMEワークフロー
定期実行の空き状況等を考慮し、3月2日の早朝5時に処理させることにしたので、2日前の日付にシフトしています。まず、Create Date&Time Rangeノードで「今日」の日付を作成し、Date&Time ShiftノードのShift Value Selection「Use Numerical」でGranularity「Days」、valueを「-2」の設定でシフトさせることができます。その後、2日前の日付を変数変換し、Variable to Table Columnノードでテーブルへカラムとして列追加しました。
②不要なデータの削除
分析に必要のないデータを精査しました。まず、今回源泉に利用したデータは、見込と実績に加えて予算のデータを保持していました。一方で、日次で変化するデータは見込と実績のみであり、予算は年に二回ほどしか更新されないため、予算のデータは削除する事にしました。図2のDB Row Filterノードで処理しており、データ全体の3割ほどが軽減されました。
続いて、前々年度のデータも削除する事にしました。今回の分析の目的は任意の時点での見込を比較することであり、基本的に前年度以前の時点のデータに対するニーズは低かったのですが、検討段階と言うこともありますので、念のため前年度のデータまでは残し、前々年度のデータは削除する方針としました。年に一度、図3の処理を実行することで行削除する計画です。①と類似の方法で、「今日」の日付を作成し、2年前にシフトさせ、その後変数に変換して条件指定し行削除する流れなのですが(図3参照)、分析は会計年度で実施するため、「今日の会計年度」を作成する工程を挟んでいます(図4参照)。今日の日付を3カ月前の日付にシフトして、String Manipulationノード「substr($date$, 0, 4)」で年の箇所を切り出せば、簡単に「今日の会計年度」を作成できます。その後、年度を日付として扱って①のDate&Time Shiftノードでシフトさせても良いですし、今回は数値型のままMath Formulaノード「$TODAY_FY$-2」でシフトさせました。このデータを使って、DB Table Selectorノード「SELECT * FROM #table# where NOT “FY” = \({S-2_FY}\)」の処理により、前々年度の行削除は完了です。

図3:前々年度の行を削除するKNIMEワークフロー
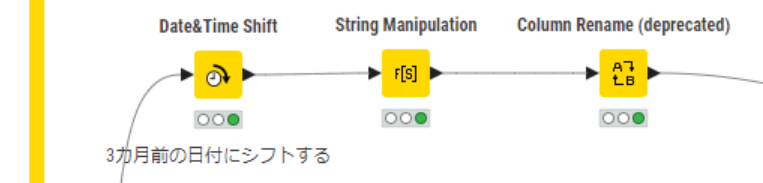
図4:「今日の会計年度」を作成するKNIMEワークフロー
なお、データハッカソンの際には上記のワークフローを作成したのですが、実際に定期実行のトライアルを開始する際には、この削除の処理はcDWH側の機能として実行することとし、KNIMEのフローからは除きました。実行の頻度が年に一度と少なく、またデータ量が多くてKNIME処理への過大な負荷が想定されたためです。
③データベース上での操作
KNIMEでデータベース操作をする際には、データベースノードを利用します。ポートの形が三角ではなく四角のものです。(赤や赤茶色をしています)DB ConnectorノードやOracle Connectorノードなどでデータベースに接続することができ、また必要な範囲のデータを切り出すような処理についても、データベースノードを使うことでKNIMEにデータをダウンロードすることなく、DB上で処理させることが出来ます。また、図2のようなDB Table SelectorノードやDB Row Filterノードなど、簡単な加工に対応できるノードが用意されていますし、SQLに慣れている方は、DB QueryノードでSQL Statementを使うことも出来ます。今回の設計でも、ワークフローの前段部分はデータベースノードを使って②の条件で必要なデータだけを切り出し、①のカラム追加する直前で、DB ReaderノードによりKNIMEにデータをロードし加工する設計としています。(図1参照)
終わりに
以上、データハッカソンで直面した経理データの「貯め方」に対する課題に対して、CDM基盤を活用して技術検討し、データ蓄積のトライアルを開始できた事例をご紹介しました。現在、このワークフローで定期実行し、日次でデータは行追加され、cDWHにデータが蓄積されています。1年ほど経過した後データ分析してみて、新たな視点で課題を浮き彫りにできるか、業務に使えるかなど検証する予定です。
ちなみに、KNIMEの定期実行は、KNIME Business Hubのアプリを通じて簡単に依頼できる仕組みにしています。図5のように分かりやすくてユーザビリティが高いだけでなく、形式化されることで依頼ミスも減りました。
図5:KNIMEの定期実行依頼アプリ画面
こだわりの詰まったCDM基盤は、私たちデータエンジニアにとって今や無くてはならない相棒と言えます。加えて、使えるデータを設計するためには、業務担当者のニーズを丁寧に精査できるデータリテラシースキルも欠かせないことを、今回改めて実感しました。データリテラシースキルは座学だけでは身に付きづらく、成長には実践経験の繰り返しが非常に重要です。これからも、データハッカソンのような機会を上手く利用し、スキルアップしていきたいです。また別のデータの事例が纏まりましたら、別の機会に紹介したいと思います。
データエンジニアリング人材の募集
データサイエンス部では、 データエンジニアリング職の募集を行っています。
データ関連のスキルやご経験をヘルスケア領域の データ基盤の構築・運用で活かしてみたい方は、 以下のリンクから募集内容の詳細を確認ください。 皆さまからのご応募をお待ちしております。
