2024年11月25日
SHIONOGIデータ基盤の構成と機能
塩野義製薬株式会社DX推進本部データサイエンス部所属、データエンジニアの直原です。 本記事では、データサイエンス部が運営するSHIONOGIデータ基盤(Central Data Management Platform)の特徴と、私たちデータエンジニアが、業務担当者やIT担当者とどのように関わっているか、についてご紹介します。
SHIONOGI は中期経営計画 “STS2030 Revision” において、”ヘルスケアサービスとしての価値提供 (Healthcare as a Service: HaaS)” を掲げた通り、ヘルスケアプロバイダーとして社会に価値を提供することを目指しています。 その中で社内のデータエンジニアは、自社が注力している感染症領域・中枢神経領域のデータを中心に、サンプルダッシュボードを作成しながら業務担当者と可視化のポイントを整理し、必要となるデータの収集およびモデリングに取り組んでいます。 また、社内の業務システムが保有しているデータを分析用に変換し、活用可能な状態で蓄積することも自分達で行います。もちろん、データ品質を確保するために欠かせない文書の作成も実施します。 これらの活動では、業務担当者だけでなく、IT担当者と協働しながら、データによる速やかな課題設定と問題解決に繋げています。
この、データ収集・活用のサイクルを円滑に回転させるために欠かせないのが、データ活用基盤です。社会環境の変化とともに、業務の要望は移り変わります。また、技術の進歩とともに、業務システムも進化します。そのような変化にも柔軟に対応できる内製化の仕組み、これを支えるスケーラビリティとユーザビリティが、私たちの基盤の最大の魅力です。例えばデータ蓄積層では、スケーラビリティを高めることでデータ処理を高速化し、業務課題の原因や対策について深掘りする際の、パフォーマンスを最大化することにこだわっています。またETLには、ノーコードで開発可能なGUIツールを採用することにより、スキル習得や運用引継ぎに対するハードルを下げ、特定のスキル保有メンバーに依存しない環境づくりを手助けしています。業務プロセスの見直しを検討する中で、データハンドリングのプロセスをGUIツールによって見える化し、業務側の専門家と共にワークフロー検討を進めることで、円滑な問題解決に繋がるケースも、見られるようになりました。 下記がデータアーキテクチャです。
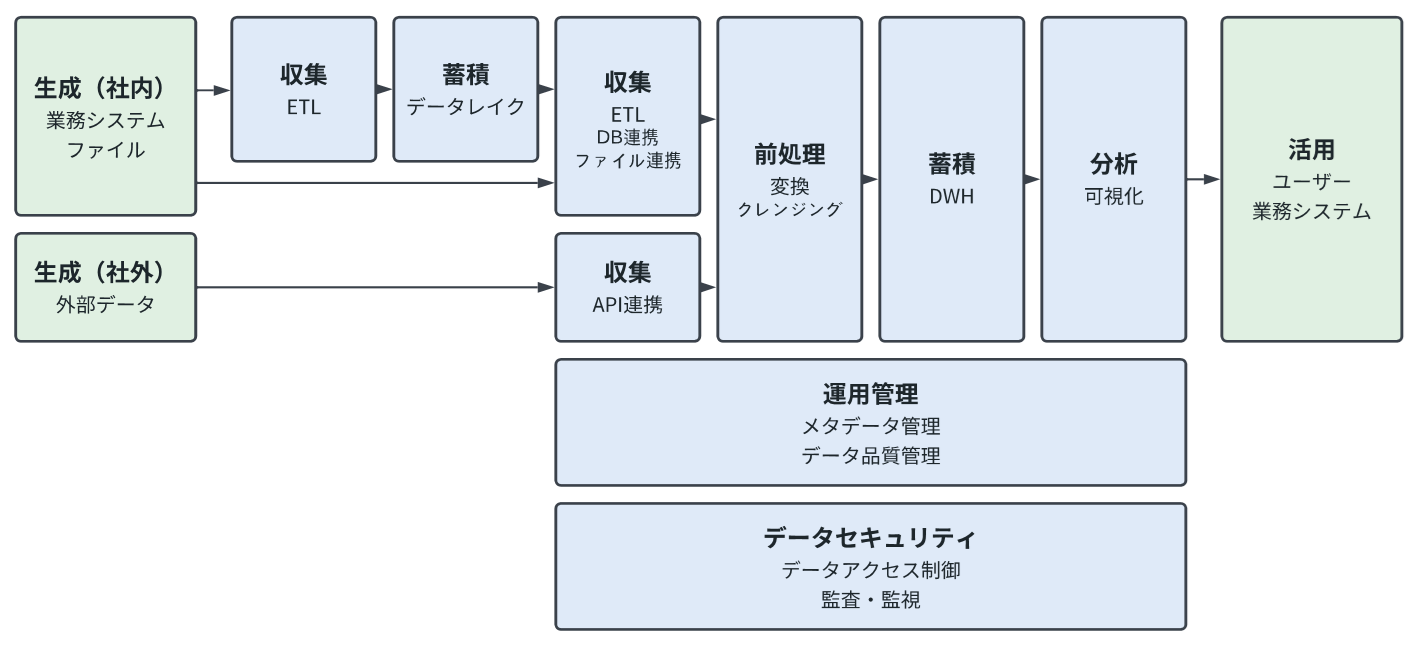
機能全体構成
SHIONOGIデータ基盤は、2種の蓄積層を中心に構成している点が特徴です。1つは、社内の業務システムをソースに、データを一旦貯めておくデータレイク、もう1つは、データレイクからデータを収集、前処理し、分析しやすい形で蓄積しておくデータウェアハウスです。業務システム間のデータ連携は、システムの新規導入や刷新を機に構築され、必ずしも分析したいタイミングとは一致しないため、データレイクを社内システムのデータハブとして機能させています。一方、業務課題の解決のための分析に必要なデータは、データレイクからデータウェアハウスに取り込みます。外部データなどデータレイクにないデータについては、Web API等を利用し、直接データウェアハウスに格納します。このデータハブとしてのデータレイクと、データ分析のためのデータウェアハウスという2種の蓄積層を中心に回転する歯車を嚙合わせることで、柔軟性を担保しながら、データに基づく速やかな意思決定に繋げています。
このSHIONOGIデータ基盤の両輪であるデータレイクとデータウェアハウスを繋ぐ要として機能しているのがETLツールとしての「KNIME」です。KNIMEは、データ収集機能としてデータベース連携やファイル連携、Web API連携を可能としているだけでなく、データ変換やクレンジングなどの前処理、可視化といった分析まで対応可能な約4,000を超える豊富なノードを保有しています。また、オープンソースプラットフォームとして最新の技術を取り入れながらノードの種類を増やしています。これらの多様なノードを自在に組み合わせることで、状況に応じたワークフローを構築できることが採用した理由です。また一般的に、データ処理の高度化に伴いワークフローのブラックボックス化が進み、運用管理が難しくなりますが、GUIによりデータ処理内容を可視化することによって属人化のリスクを低減させ、担当者引継ぎに対する負担を軽減できること、注釈などの日本語化によりユーザーフレンドリーであることも、採用理由の1つです。本稿では、データ基盤の機能のうち、このKNIMEを活用したETL処理に関係する部分にフォーカスして、以下に詳細を示します。
1. データレイクからデータを収集する
上述の通り、データレイクとデータウェアハウスは用途が異なるため、互いに独立して管理され、制御されています。データレイクからデータを収集する際にも、KNIMEでデータベース連携を構築します。また、データレイク保有のデータは、社内の業務システム由来の社内活動に関するデータが中心であり、これらは、定期的なモニタリング活動の一環として可視化・分析されるため、バッチ処理を基本としています。データエンジニアは、データの用途に応じて適切な更新頻度を設定することによってデータウェアハウスの鮮度を保っています。
2. 業務システム由来のデータを分析用に変換する
データレイクからデータウェアハウスにデータを格納する場合、対象となるデータは基本的に構造化データなので、前処理はシンプルです。業務システム特有の項目削除や導出項目の付与など情報の過不足を補い整えること、汎用化のための正規化や、高度に正規化されている場合には非正規化すること、データの縦持ち横持ち変換、項目名に対する命名規則の適用などです。用途次第では、データを抽出し、分類し、集計するといったこともします。 各データエンジニアは、KNIMEで作成したワークフローをチーム内で共有し、「壁打ち」します。データに関する知識やデータ設計のアイデア、効率的な処理ロジック、KNIMEのノード活用に関するTipsなどをチームメンバへ紹介し、自身の理解を深めると同時に、指摘してもらうことでより良い設計を目指します。ワークフローそのものも参加者に共有され、メンバーが再利用することも可能です。
3. 整備したデータを整理してデータウェアハウスへ格納する
データウェアハウスでは、データ同士を組み合わせて分析しやすいように、「組織」「会計」「営業」のように区分けして蓄積しています。整備したデータをデータウェアハウスに格納する際には、データカタログを参照しながら各区分にどのようなデータが格納されているか確認し、データの使いどころに照らして、どこに格納するかを選択します。適合する区分がない場合には、後述の運用管理のプロセスの中で、追加作成します。
4. データウェアハウスのデータの品質を維持管理する
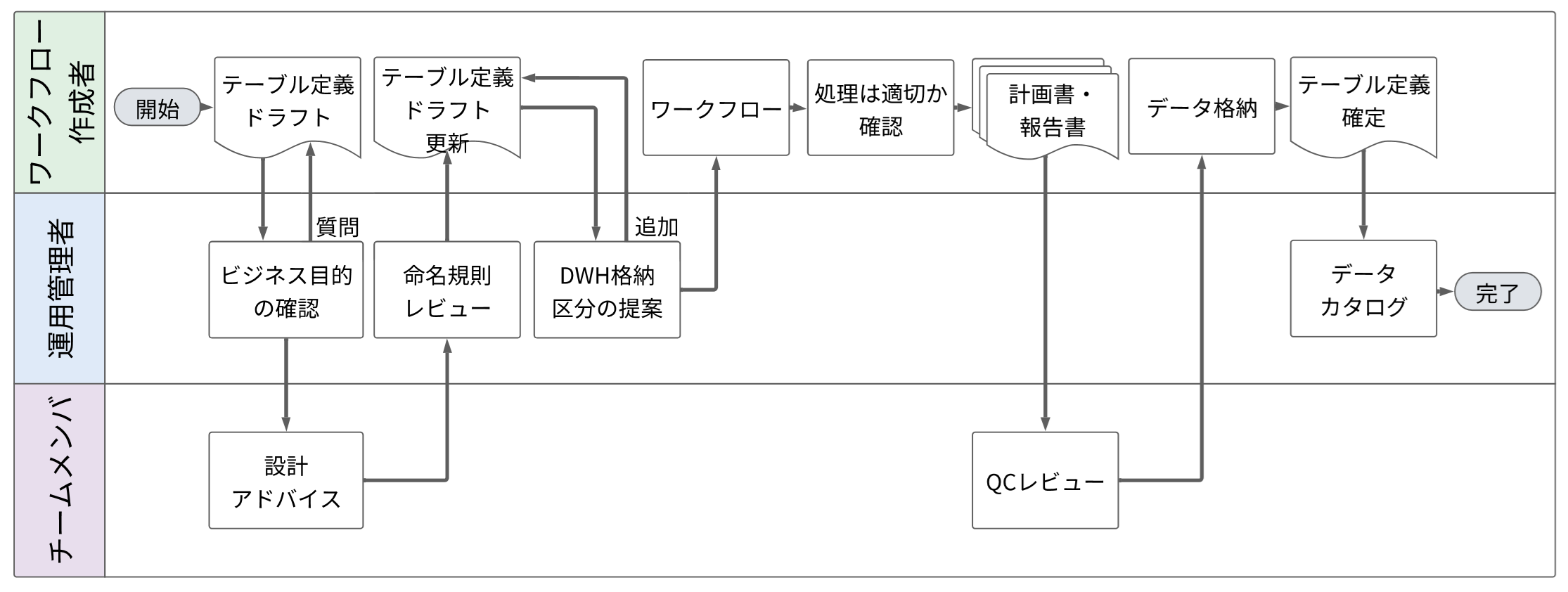
データウェアハウスの運営では、KNIMEによるデータの収集、変換、格納の一連のプロセスを理解し、確認し、記述することで、データの品質を維持管理しています。具体的には、標準化されたテーブル定義書、ワークフローのチェックリスト、テスト計画・報告書といったドキュメントによる管理を採用しています。テーブル定義書の作成には、データウェアハウスの運用管理者が関与し、命名規則などに基づいて論理名や物理名をレビューし項目名を一定基準のもと標準化することで、データウェアハウスの検索性を高めています。また、ワークフロー作成者は、データ格納に至るロジックに誤りがないかテストを行うとともに、品質基準を満たしていることをチェックリストで自己点検します。更に、自分以外のチームメンバもテスト計画・報告書をレビューし、実行時の再現性を確認することで、信頼性の高いデータの安定供給を確立しています。
5. データウェアハウスのデータへのアクセスをコントロールする
データレイクのデータは、社内の業務システムから直接連携されてくるため、機密情報を多く含みます。したがって、データレイクに対するアクセスは、社内の各業務システムによる直接的なアクセスと、IT担当者およびデータエンジニアによるアクセスに限定し、情報漏洩のリスクが最小限になるよう制御しています。一方、データ活用の中心であるデータサイエンティストあるいは業務担当者はデータウェアハウスにアクセスし、各々が持つ業務課題の解決に向けてデータを分析します。このためデータウェアハウスでは、行レベルや列レベルでの認可が可能であり、あらゆるユーザによるデータアクセスを監視するための監査レポート機能を有する、柔軟性の高いシステムを採用しています。また、データ分析者がデータウェアハウスのデータにアクセスする際には、誰がどのような目的でどのデータを使用したいのかについて事前に申請します。その上で、データオーナー承認のもと、適切なアクセス権を払い出しています。
終わりに
以上、SHIONOGIデータ基盤について、データレイクとデータウェアハウスを繋ぐETLツールである「KNIME」を中心に、構成と機能について紹介しました。SHIONOGIデータ基盤の強みである2つのデータ蓄積層、この両輪を繋ぐ要である「KNIME」、これを操り、業務とITをデータで繋ぐ人材が、私たちデータエンジニアです。社内の様々な業務領域の専門家やIT担当者などとの多様なコミュニケーションが求められる難しさもありますが、One Teamで成果を出すのがSHIONOGI流であり、私は働き甲斐があると感じています。 なお、今回紹介から省きました、データレイク側を中心とした内容や、業務システム以外からのデータの収集機能については、また別の機会に紹介したいと思います。
参考文献
- 『データマネジメント知識体系ガイド第二版』(DAMA International 著/DAMA 日本支部、Metafindコンサルティング株式会社 翻訳/日経BP/2018)
- 『DX時代のデータマネジメント大全』(大川真輝 著/翔泳社/2023)
データエンジニアリング人材の募集
データサイエンス部では、 データエンジニアリング職の募集を行っています。
データ関連のスキルやご経験をヘルスケア領域の データ基盤の構築・運用で活かしてみたい方は、 以下のリンクから募集内容の詳細を確認ください。 皆さまからのご応募をお待ちしております。
